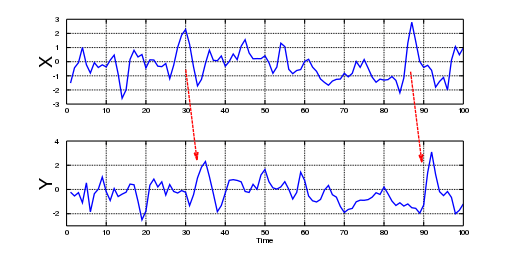
First we load and take a look at the data. The time series areconstructed as the average of the emotions expressed on Twitter in timeslots of five minutes during the 24 hours after the earthquake,therefore, every time series has 288 values.
#Set directorysetwd("C:\\Your directory")#Import the DDBB to be analyzedemotions <- read.csv("earthquakedata.csv", header = TRUE)#Plot of the time seriests.plot(emotions, col=c("cornflowerblue", "blue", "blue4","darkgoldenrod1","darkgoldenrod4" ), ylim=c(0,0.3))title(main = "Time series Southern California Earthquake", cex.main=1.5)legend("topright", legend = c("Sadness", "Anger", "Fear", "Disgust", "Joy"), cex = 1.0, bty="n", col = c("cornflowerblue", "blue", "blue4","darkgoldenrod1","darkgoldenrod4" ),lwd = 2)
Step 1
To use Granger causality correctly we need to check if the time serieswe use are stationary. For that purpose we use the Augmented DickeyFuller (ADF) and KPSS tests. In the case of ADF with a p-value smallerthan .05 we can say that a time series is stationary while for KPSS weneed a p-value greater than .05
######################### Stationarity test ##########################We load the package tseries which contains the ADF and KPSS testslibrary("tseries")adf.test(emotions$sadness)## Warning in adf.test(emotions$sadness): p-value smaller than printed p-value## ## Augmented Dickey-Fuller Test## ## data: emotions$sadness## Dickey-Fuller = -4.5096, Lag order = 6, p-value = 0.01## alternative hypothesis: stationaryadf.test(emotions$anger)## Warning in adf.test(emotions$anger): p-value smaller than printed p-value## ## Augmented Dickey-Fuller Test## ## data: emotions$anger## Dickey-Fuller = -5.2468, Lag order = 6, p-value = 0.01## alternative hypothesis: stationaryadf.test(emotions$fear)## Warning in adf.test(emotions$fear): p-value smaller than printed p-value## ## Augmented Dickey-Fuller Test## ## data: emotions$fear## Dickey-Fuller = -4.5921, Lag order = 6, p-value = 0.01## alternative hypothesis: stationaryadf.test(emotions$disgust)## Warning in adf.test(emotions$disgust): p-value smaller than printed p-value## ## Augmented Dickey-Fuller Test## ## data: emotions$disgust## Dickey-Fuller = -6.492, Lag order = 6, p-value = 0.01## alternative hypothesis: stationaryadf.test(emotions$joy)## Warning in adf.test(emotions$joy): p-value smaller than printed p-value## ## Augmented Dickey-Fuller Test## ## data: emotions$joy## Dickey-Fuller = -5.4876, Lag order = 6, p-value = 0.01## alternative hypothesis: stationarykpss.test(emotions$sadness)## ## KPSS Test for Level Stationarity## ## data: emotions$sadness## KPSS Level = 0.48228, Truncation lag parameter = 5, p-value = 0.04566kpss.test(emotions$anger)## Warning in kpss.test(emotions$anger): p-value greater than printed p-value## ## KPSS Test for Level Stationarity## ## data: emotions$anger## KPSS Level = 0.33252, Truncation lag parameter = 5, p-value = 0.1kpss.test(emotions$fear)## Warning in kpss.test(emotions$fear): p-value smaller than printed p-value## ## KPSS Test for Level Stationarity## ## data: emotions$fear## KPSS Level = 2.0727, Truncation lag parameter = 5, p-value = 0.01kpss.test(emotions$disgust)## Warning in kpss.test(emotions$disgust): p-value greater than printed p-value## ## KPSS Test for Level Stationarity## ## data: emotions$disgust## KPSS Level = 0.13877, Truncation lag parameter = 5, p-value = 0.1kpss.test(emotions$joy)## Warning in kpss.test(emotions$joy): p-value smaller than printed p-value## ## KPSS Test for Level Stationarity## ## data: emotions$joy## KPSS Level = 3.1366, Truncation lag parameter = 5, p-value = 0.01Step 2
From the previous results it is possible to notice that ADF and KPSSdon’t agree in all the results. Moreover sadness, fear, and joy arenot stationary for KPSS test. To proceed with the analysis we still needto transform the data in stationary time series. The transformation weuse is the differentiation of all the time series to keep theconsistency of the data then we analyze again if the transformed data isstationary.
######################################### Stationarity of first differences ##########################################Transformation of time seriesd_sadness <- diff(emotions$sadness)d_anger <- diff(emotions$anger)d_fear <- diff(emotions$fear)d_disgust <- diff(emotions$disgust)d_joy <- diff(emotions$joy)#New dataframe with the times series differentiatedd_emotions <- as.data.frame(cbind(d_sadness, d_anger, d_fear, d_disgust, d_joy))#Perform stationarity tests for transformed time seriesadf.test(d_emotions$d_sadness)## Warning in adf.test(d_emotions$d_sadness): p-value smaller than printed p-value## ## Augmented Dickey-Fuller Test## ## data: d_emotions$d_sadness## Dickey-Fuller = -10.683, Lag order = 6, p-value = 0.01## alternative hypothesis: stationaryadf.test(d_emotions$d_anger)## Warning in adf.test(d_emotions$d_anger): p-value smaller than printed p-value## ## Augmented Dickey-Fuller Test## ## data: d_emotions$d_anger## Dickey-Fuller = -10.585, Lag order = 6, p-value = 0.01## alternative hypothesis: stationaryadf.test(d_emotions$d_fear)## Warning in adf.test(d_emotions$d_fear): p-value smaller than printed p-value## ## Augmented Dickey-Fuller Test## ## data: d_emotions$d_fear## Dickey-Fuller = -10.255, Lag order = 6, p-value = 0.01## alternative hypothesis: stationaryadf.test(d_emotions$d_disgust)## Warning in adf.test(d_emotions$d_disgust): p-value smaller than printed p-value## ## Augmented Dickey-Fuller Test## ## data: d_emotions$d_disgust## Dickey-Fuller = -10.456, Lag order = 6, p-value = 0.01## alternative hypothesis: stationaryadf.test(d_emotions$d_joy)## Warning in adf.test(d_emotions$d_joy): p-value smaller than printed p-value## ## Augmented Dickey-Fuller Test## ## data: d_emotions$d_joy## Dickey-Fuller = -10.625, Lag order = 6, p-value = 0.01## alternative hypothesis: stationarykpss.test(d_emotions$d_sadness)## Warning in kpss.test(d_emotions$d_sadness): p-value greater than printed p-value## ## KPSS Test for Level Stationarity## ## data: d_emotions$d_sadness## KPSS Level = 0.017846, Truncation lag parameter = 5, p-value = 0.1kpss.test(d_emotions$d_anger)## Warning in kpss.test(d_emotions$d_anger): p-value greater than printed p-value## ## KPSS Test for Level Stationarity## ## data: d_emotions$d_anger## KPSS Level = 0.11013, Truncation lag parameter = 5, p-value = 0.1kpss.test(d_emotions$d_fear)## Warning in kpss.test(d_emotions$d_fear): p-value greater than printed p-value## ## KPSS Test for Level Stationarity## ## data: d_emotions$d_fear## KPSS Level = 0.036515, Truncation lag parameter = 5, p-value = 0.1kpss.test(d_emotions$d_disgust)## Warning in kpss.test(d_emotions$d_disgust): p-value greater than printed p-value## ## KPSS Test for Level Stationarity## ## data: d_emotions$d_disgust## KPSS Level = 0.03343, Truncation lag parameter = 5, p-value = 0.1kpss.test(d_emotions$d_joy)## Warning in kpss.test(d_emotions$d_joy): p-value greater than printed p-value## ## KPSS Test for Level Stationarity## ## data: d_emotions$d_joy## KPSS Level = 0.011566, Truncation lag parameter = 5, p-value = 0.1Step 3
Once all the time series comply with the requirement of stationarity weneed to select the appropiate number of lags for the analysis.
##################### Lag selection ######################We use the tsDyn package for the analysisvar_lag <- tsDyn::lags.select(d_emotions)var_lag## Best AIC: lag= 10 ## Best BIC: lag= 2 ## Best HQ : lag= 4From the previous result we incorporate a lag of 2 in the analysis basedon BIC criterion. The reason to select BIC is that this criterion triesto find the true model among the set of candidates plus from thestructure of the data it makes sense to include tweets from two timeslots in the past which represents 10 minutes instead of 20 or 50minutes which are the options of HQ and AIC criterion respectively.
Step 4
It was mentioned that our interest was to find if it was possible topredict the appearence of one emotion based in the previous expressionof other emotions. Following a data driven approach we used a methodcalled Vector Auto Regresive (VAR) analysis to identify what emotionsmake predictions on others. The use of the VAR method allow us toincorporate a multivariate analysis for each emotion. For example, wetry to predict sadness with information from the past of sadness itselfplus anger, fear, disgust, and joy in the same model, then the resulttell us what emotions are significant for the prediction of sadness.Let’s assume that in this case the only significant emotion to predictsadness is anger but because of the multivariate nature of the VARanalysis it is hard to make an interpretation of the relationshipbetween them. At this point we move forward to make a Granger causalanalysis between sadness and anger that can be interpreted consideringwhat we have learned in this post.
#################### VAR analysis #####################We load vars package to perform the analysislibrary("vars")var_results <- VAR(d_emotions, p = 2) #p=2 refers to the maximum lag selectedsummary(var_results)## ## VAR Estimation Results:## ========================= ## Endogenous variables: d_sadness, d_anger, d_fear, d_disgust, d_joy ## Deterministic variables: const ## Sample size: 285 ## Log Likelihood: 3641.218 ## Roots of the characteristic polynomial:## 0.6317 0.6317 0.6183 0.6183 0.585 0.585 0.5751 0.5751 0.3746 0.3746## Call:## VAR(y = d_emotions, p = 2)## ## ## Estimation results for equation d_sadness: ## ========================================== ## d_sadness = d_sadness.l1 + d_anger.l1 + d_fear.l1 + d_disgust.l1 + d_joy.l1 + d_sadness.l2 + d_anger.l2 + d_fear.l2 + d_disgust.l2 + d_joy.l2 + const ## ## Estimate Std. Error t value Pr(>|t|) ## d_sadness.l1 -0.6953898 0.0585405 -11.879 < 2e-16 ***## d_anger.l1 0.0347770 0.0858959 0.405 0.6859 ## d_fear.l1 -0.0470720 0.0724411 -0.650 0.5164 ## d_disgust.l1 0.1624978 0.1206383 1.347 0.1791 ## d_joy.l1 -0.0949055 0.0564832 -1.680 0.0940 . ## d_sadness.l2 -0.3730392 0.0585910 -6.367 8.1e-10 ***## d_anger.l2 0.0731065 0.0849923 0.860 0.3905 ## d_fear.l2 -0.1260265 0.0725353 -1.737 0.0834 . ## d_disgust.l2 -0.0638156 0.1213525 -0.526 0.5994 ## d_joy.l2 -0.0795697 0.0570315 -1.395 0.1641 ## const 0.0001768 0.0014627 0.121 0.9039 ## ---## Signif. codes: 0 "***" 0.001 "**" 0.01 "*" 0.05 "." 0.1 " " 1## ## ## Residual standard error: 0.02467 on 274 degrees of freedom## Multiple R-Squared: 0.3689, Adjusted R-squared: 0.3459 ## F-statistic: 16.02 on 10 and 274 DF, p-value: < 2.2e-16 ## ## ## Estimation results for equation d_anger: ## ======================================== ## d_anger = d_sadness.l1 + d_anger.l1 + d_fear.l1 + d_disgust.l1 + d_joy.l1 + d_sadness.l2 + d_anger.l2 + d_fear.l2 + d_disgust.l2 + d_joy.l2 + const ## ## Estimate Std. Error t value Pr(>|t|) ## d_sadness.l1 -0.0557819 0.0427400 -1.305 0.192939 ## d_anger.l1 -0.4504857 0.0627119 -7.183 6.43e-12 ***## d_fear.l1 0.0974610 0.0528887 1.843 0.066445 . ## d_disgust.l1 0.1366864 0.0880771 1.552 0.121842 ## d_joy.l1 0.0700432 0.0412380 1.699 0.090546 . ## d_sadness.l2 -0.0408431 0.0427769 -0.955 0.340523 ## d_anger.l2 -0.2173795 0.0620522 -3.503 0.000537 ***## d_fear.l2 0.0133412 0.0529575 0.252 0.801289 ## d_disgust.l2 -0.0451519 0.0885986 -0.510 0.610726 ## d_joy.l2 -0.0300140 0.0416383 -0.721 0.471630 ## const -0.0004434 0.0010679 -0.415 0.678298 ## ---## Signif. codes: 0 "***" 0.001 "**" 0.01 "*" 0.05 "." 0.1 " " 1## ## ## Residual standard error: 0.01801 on 274 degrees of freedom## Multiple R-Squared: 0.2279, Adjusted R-squared: 0.1997 ## F-statistic: 8.088 on 10 and 274 DF, p-value: 1.922e-11 ## ## ## Estimation results for equation d_fear: ## ======================================= ## d_fear = d_sadness.l1 + d_anger.l1 + d_fear.l1 + d_disgust.l1 + d_joy.l1 + d_sadness.l2 + d_anger.l2 + d_fear.l2 + d_disgust.l2 + d_joy.l2 + const ## ## Estimate Std. Error t value Pr(>|t|) ## d_sadness.l1 -1.168e-02 5.100e-02 -0.229 0.8190 ## d_anger.l1 1.222e-01 7.483e-02 1.633 0.1036 ## d_fear.l1 -5.181e-01 6.311e-02 -8.210 8.77e-15 ***## d_disgust.l1 3.388e-02 1.051e-01 0.322 0.7474 ## d_joy.l1 1.278e-02 4.921e-02 0.260 0.7953 ## d_sadness.l2 1.175e-01 5.104e-02 2.302 0.0221 * ## d_anger.l2 1.415e-02 7.404e-02 0.191 0.8485 ## d_fear.l2 -2.531e-01 6.319e-02 -4.006 7.96e-05 ***## d_disgust.l2 8.289e-02 1.057e-01 0.784 0.4337 ## d_joy.l2 -4.362e-02 4.968e-02 -0.878 0.3808 ## const -6.722e-05 1.274e-03 -0.053 0.9580 ## ---## Signif. codes: 0 "***" 0.001 "**" 0.01 "*" 0.05 "." 0.1 " " 1## ## ## Residual standard error: 0.02149 on 274 degrees of freedom## Multiple R-Squared: 0.2594, Adjusted R-squared: 0.2324 ## F-statistic: 9.599 on 10 and 274 DF, p-value: 1.048e-13 ## ## ## Estimation results for equation d_disgust: ## ========================================== ## d_disgust = d_sadness.l1 + d_anger.l1 + d_fear.l1 + d_disgust.l1 + d_joy.l1 + d_sadness.l2 + d_anger.l2 + d_fear.l2 + d_disgust.l2 + d_joy.l2 + const ## ## Estimate Std. Error t value Pr(>|t|) ## d_sadness.l1 1.252e-02 2.911e-02 0.430 0.667 ## d_anger.l1 -2.278e-02 4.271e-02 -0.533 0.594 ## d_fear.l1 -4.157e-02 3.602e-02 -1.154 0.249 ## d_disgust.l1 -5.783e-01 5.999e-02 -9.639 < 2e-16 ***## d_joy.l1 3.125e-02 2.809e-02 1.113 0.267 ## d_sadness.l2 -1.456e-02 2.914e-02 -0.500 0.618 ## d_anger.l2 1.587e-02 4.226e-02 0.376 0.708 ## d_fear.l2 -3.213e-02 3.607e-02 -0.891 0.374 ## d_disgust.l2 -3.645e-01 6.035e-02 -6.041 4.99e-09 ***## d_joy.l2 7.515e-03 2.836e-02 0.265 0.791 ## const 4.957e-05 7.273e-04 0.068 0.946 ## ---## Signif. codes: 0 "***" 0.001 "**" 0.01 "*" 0.05 "." 0.1 " " 1## ## ## Residual standard error: 0.01227 on 274 degrees of freedom## Multiple R-Squared: 0.295, Adjusted R-squared: 0.2692 ## F-statistic: 11.46 on 10 and 274 DF, p-value: < 2.2e-16 ## ## ## Estimation results for equation d_joy: ## ====================================== ## d_joy = d_sadness.l1 + d_anger.l1 + d_fear.l1 + d_disgust.l1 + d_joy.l1 + d_sadness.l2 + d_anger.l2 + d_fear.l2 + d_disgust.l2 + d_joy.l2 + const ## ## Estimate Std. Error t value Pr(>|t|) ## d_sadness.l1 0.1160292 0.0606994 1.912 0.056978 . ## d_anger.l1 0.0070177 0.0890635 0.079 0.937254 ## d_fear.l1 -0.0447704 0.0751125 -0.596 0.551637 ## d_disgust.l1 -0.2522966 0.1250871 -2.017 0.044674 * ## d_joy.l1 -0.6090107 0.0585661 -10.399 < 2e-16 ***## d_sadness.l2 0.1404621 0.0607517 2.312 0.021515 * ## d_anger.l2 -0.3321738 0.0881266 -3.769 0.000201 ***## d_fear.l2 -0.1014774 0.0752102 -1.349 0.178370 ## d_disgust.l2 -0.0672985 0.1258276 -0.535 0.593190 ## d_joy.l2 -0.3127464 0.0591347 -5.289 2.52e-07 ***## const -0.0003091 0.0015166 -0.204 0.838678 ## ---## Signif. codes: 0 "***" 0.001 "**" 0.01 "*" 0.05 "." 0.1 " " 1## ## ## Residual standard error: 0.02558 on 274 degrees of freedom## Multiple R-Squared: 0.3708, Adjusted R-squared: 0.3478 ## F-statistic: 16.15 on 10 and 274 DF, p-value: < 2.2e-16 ## ## ## ## Covariance matrix of residuals:## d_sadness d_anger d_fear d_disgust d_joy## d_sadness 6.087e-04 3.678e-05 1.031e-04 2.280e-05 -1.436e-04## d_anger 3.678e-05 3.245e-04 7.150e-05 3.134e-05 -1.338e-04## d_fear 1.031e-04 7.150e-05 4.619e-04 -4.951e-05 -6.023e-05## d_disgust 2.280e-05 3.134e-05 -4.951e-05 1.505e-04 -4.690e-06## d_joy -1.436e-04 -1.338e-04 -6.023e-05 -4.690e-06 6.544e-04## ## Correlation matrix of residuals:## d_sadness d_anger d_fear d_disgust d_joy## d_sadness 1.00000 0.08277 0.1945 0.07533 -0.22756## d_anger 0.08277 1.00000 0.1847 0.14180 -0.29041## d_fear 0.19448 0.18468 1.0000 -0.18776 -0.10954## d_disgust 0.07533 0.14180 -0.1878 1.00000 -0.01494## d_joy -0.22756 -0.29041 -0.1095 -0.01494 1.00000Step 5
Now that the VAR analysis help us to identify significant relationshipsbetween emotions. We procede to perform the Granger causal analysisbetween fear/sadness, joy/anger, joy/sadness, and joy/disgust.
############################################################ Revising significant relationships Granger causality #############################################################We perform all the pairwise granger causality analysisgrangertest(d_emotions$d_fear ~ d_emotions$d_sadness, order=2) #order=2 refers to the maximum lag selected ## Granger causality test## ## Model 1: d_emotions$d_fear ~ Lags(d_emotions$d_fear, 1:2) + Lags(d_emotions$d_sadness, 1:2)## Model 2: d_emotions$d_fear ~ Lags(d_emotions$d_fear, 1:2)## Res.Df Df F Pr(>F) ## 1 280 ## 2 282 -2 4.5796 0.01104 *## ---## Signif. codes: 0 "***" 0.001 "**" 0.01 "*" 0.05 "." 0.1 " " 1grangertest(d_emotions$d_sadness ~ d_emotions$d_fear, order=2)## Granger causality test## ## Model 1: d_emotions$d_sadness ~ Lags(d_emotions$d_sadness, 1:2) + Lags(d_emotions$d_fear, 1:2)## Model 2: d_emotions$d_sadness ~ Lags(d_emotions$d_sadness, 1:2)## Res.Df Df F Pr(>F)## 1 280 ## 2 282 -2 1.305 0.2728grangertest(d_emotions$d_joy ~ d_emotions$d_anger, order=2)## Granger causality test## ## Model 1: d_emotions$d_joy ~ Lags(d_emotions$d_joy, 1:2) + Lags(d_emotions$d_anger, 1:2)## Model 2: d_emotions$d_joy ~ Lags(d_emotions$d_joy, 1:2)## Res.Df Df F Pr(>F) ## 1 280 ## 2 282 -2 8.2868 0.0003188 ***## ---## Signif. codes: 0 "***" 0.001 "**" 0.01 "*" 0.05 "." 0.1 " " 1grangertest(d_emotions$d_anger ~ d_emotions$d_joy, order=2)## Granger causality test## ## Model 1: d_emotions$d_anger ~ Lags(d_emotions$d_anger, 1:2) + Lags(d_emotions$d_joy, 1:2)## Model 2: d_emotions$d_anger ~ Lags(d_emotions$d_anger, 1:2)## Res.Df Df F Pr(>F) ## 1 280 ## 2 282 -2 3.1286 0.04532 *## ---## Signif. codes: 0 "***" 0.001 "**" 0.01 "*" 0.05 "." 0.1 " " 1grangertest(d_emotions$d_joy ~ d_emotions$d_sadness, order=2)## Granger causality test## ## Model 1: d_emotions$d_joy ~ Lags(d_emotions$d_joy, 1:2) + Lags(d_emotions$d_sadness, 1:2)## Model 2: d_emotions$d_joy ~ Lags(d_emotions$d_joy, 1:2)## Res.Df Df F Pr(>F)## 1 280 ## 2 282 -2 2.0109 0.1358grangertest(d_emotions$d_sadness ~ d_emotions$d_joy, order=2)## Granger causality test## ## Model 1: d_emotions$d_sadness ~ Lags(d_emotions$d_sadness, 1:2) + Lags(d_emotions$d_joy, 1:2)## Model 2: d_emotions$d_sadness ~ Lags(d_emotions$d_sadness, 1:2)## Res.Df Df F Pr(>F)## 1 280 ## 2 282 -2 1.5771 0.2084grangertest(d_emotions$d_joy ~ d_emotions$d_disgust, order=2)## Granger causality test## ## Model 1: d_emotions$d_joy ~ Lags(d_emotions$d_joy, 1:2) + Lags(d_emotions$d_disgust, 1:2)## Model 2: d_emotions$d_joy ~ Lags(d_emotions$d_joy, 1:2)## Res.Df Df F Pr(>F)## 1 280 ## 2 282 -2 0.9428 0.3908grangertest(d_emotions$d_disgust ~ d_emotions$d_joy, order=2)## Granger causality test## ## Model 1: d_emotions$d_disgust ~ Lags(d_emotions$d_disgust, 1:2) + Lags(d_emotions$d_joy, 1:2)## Model 2: d_emotions$d_disgust ~ Lags(d_emotions$d_disgust, 1:2)## Res.Df Df F Pr(>F)## 1 280 ## 2 282 -2 0.9252 0.3977Results
From the final results of this example it is possible to appreciate thatSadness Granger causes Fear, which means that the expression of Sadnessin the aftermath of the Southern California earthquake predicts theexpression of Fear moments later. I also found that the relationshipbetween Anger and Joy is statistically significant in both ways whichcould mean that the expression of those emotions generate a loop betweenthem.The relationships between Joy and Sadness, and Joy and Disgust thatwere significant in the VAR analysis were not when I performed theGranger causality test.